
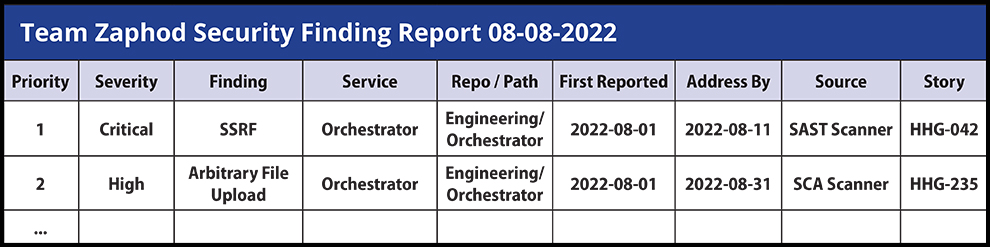
Clearly outlining issues and requirements is an essential step in properly managing any AppSec program to effectively reduce security risk. Giving Engineering a clear road map and punch list of issues is necessary to properly engage and motivate them to take action. Framing it in the context of the project management tools, application sprint schedules and organizational priorities will help developers work security changes into their daily habits.
This isn’t easy. Several elements need to be established to achieve this level of clarity and build the foundation for a comprehensive view of potential threats. One such challenge is creating a central asset inventory system “data lake” or “data warehouse” that can be used to collect and relate the necessary data from a variety of sources. You can also use a product like Fivetran to assist with the extract, load, and transformation (ELT) of this data. Setting up a system like this will likely require involvement by more than just the security team – and the good news is that many of the best practices used to create this curated list for engineers can assist in managing an organization’s overall inventory needs. In other words, the work required to help prioritize security issues is also work that will help run the organization more efficiently overall.
As the President’s Executive Order on Improving the Nation’s Cybersecurity noted, “The development of commercial software often lacks transparency, sufficient focus on the ability of the software to resist attack, and adequate controls to prevent tampering by malicious actors. There is a pressing need to implement more rigorous and predictable mechanisms for ensuring that products function securely, and as intended.”
Preparing for the unexpected will always be a challenge for security professionals and tracking the latest threats will often call for immediate action. If you maintain a current accounting of your systems and data streams, then when you find IoCs, you will know the potential points of weakness in your architecture, and what areas to protect immediately.
Better still, if you’re able to provide your engineering teams clear, actionable tasks in a format they can understand and integrate into their workflow, you may be able to prevent these attacks from happening in the first place. ![]()
Leave a Comment